文学
kprobe
pycharm
安全测试
vr
dxf
小端
充放电
控制算法
暴力
基本指令
bi
敖丙
CalBioreagents
队列
IDEA 常用插件
javaee
企业人事管理系统
.Net6
地图模拟数据
分布式训练
2024/4/12 2:09:28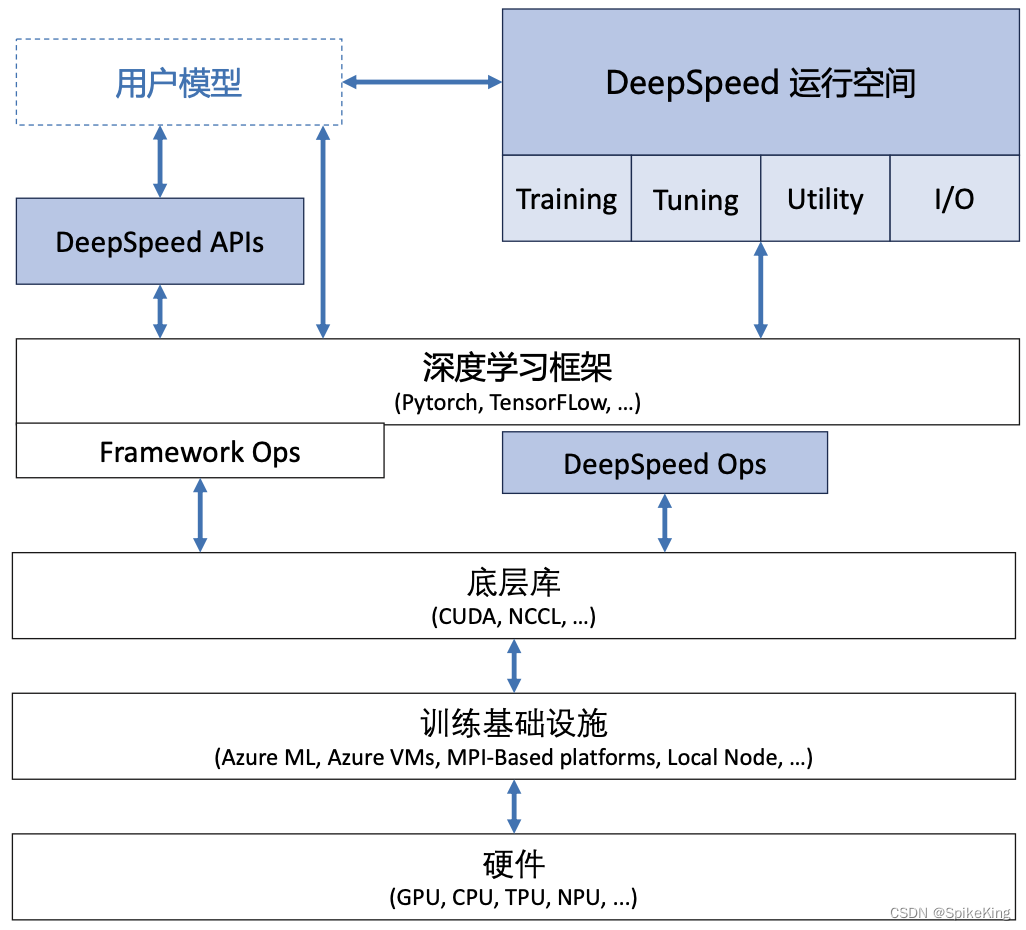
LLM - 大语言模型的分布式训练 概述
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://blog.csdn.net/caroline_wendy/article/details/136924304 大语言模型的分布式训练是一个复杂的过程,涉及到将大规模的计算任务分散到多个计算节点上。这样做的目的是为了处…

Pytorch分布式数据并行(DistributedDataParallel)
1 初始化进程组import os
from torch import distributedtry:world_size int(os.environ["WORLD_SIZE"]) # 全局进程个数rank int(os.environ["RANK"]) # 当前进程编号(全局)local_rank int(os.environ["LOCAL_RANK"]) # 每台机器上的进程…
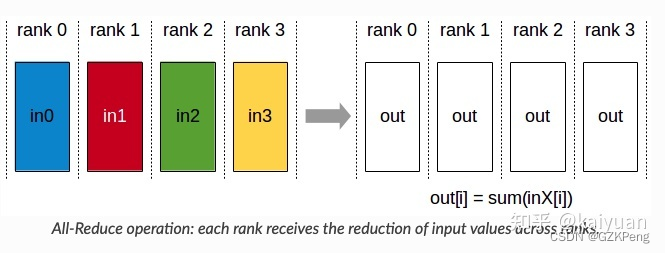
pytorch常见分布式训练报错(另备忘模型分布式后,named_modules,前会加module.)
1、–nproc_per_node设置错误,比如就2块可见卡,设置3,那么代码中这行torch.cuda.set_device(args.local_rank) 就会报以下错误
Traceback (most recent call last):File "trainDDP.py", line 32, in <module>torch.cuda.set…
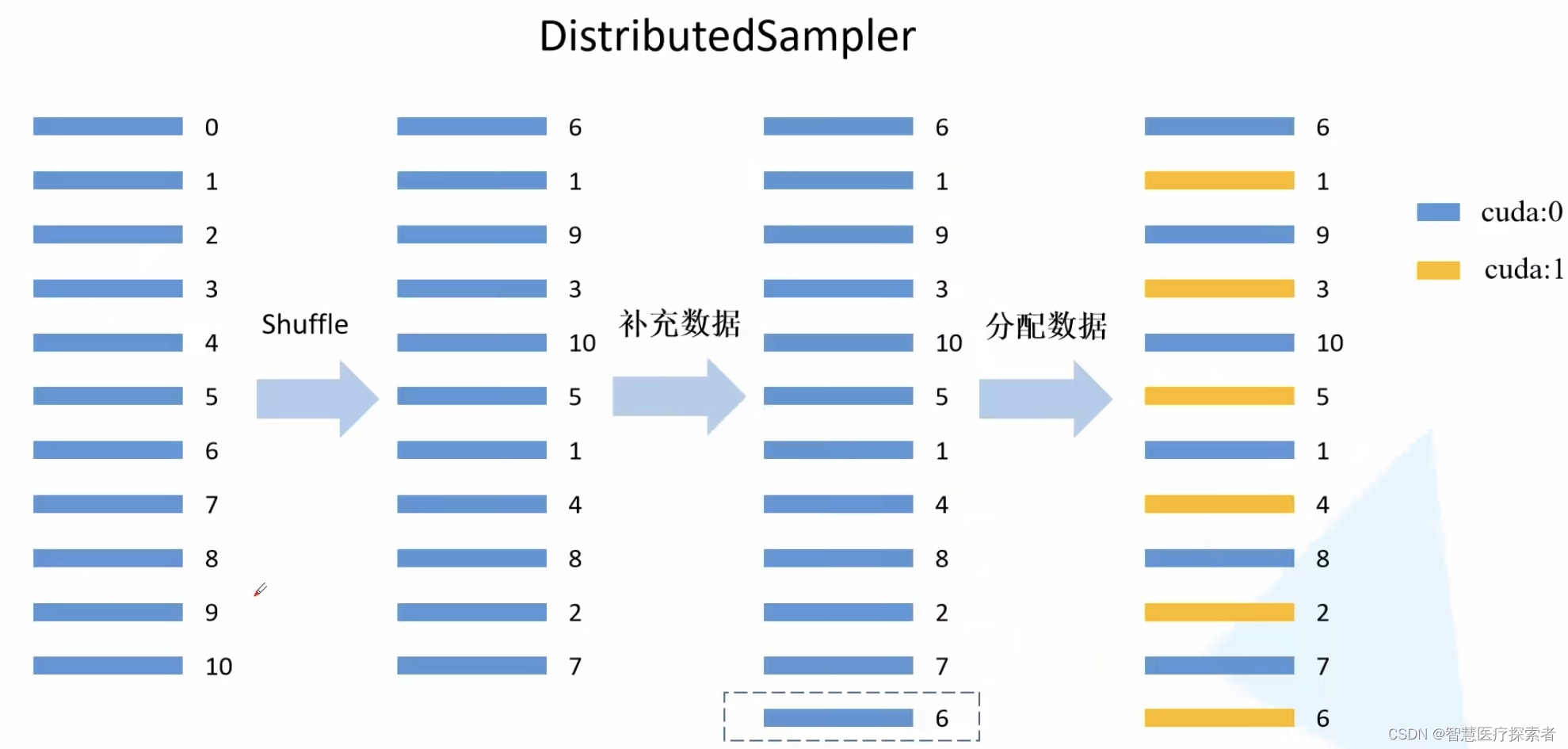
PyTorch 分布式训练 --- 数据加载之DistributedSampler
1. 一句话总结:
DDP中DistributedSampler保证测试数据集加载固定顺序,且在各个程序中都是一样时(因为shuffleTrue时使用了随机种子,不保证在各个程序中测试数据集加载顺序都是一样),最好在DistributedSamp…

分布式训练 最小化部署docker swarm + docker-compose落地方案
目录
背景:
前提条件:
一、docker环境初始化配置
1. 安装nvidia-docker2
2. 安装docker-compose工具
3. 获取GPU UUID
4. 修改docker runtime为nvidia,指定机器的UUID
二、docker-swarm 环境安装
1. 初始化swarm管理节点
2. 加入工…

使用hugging face开源库accelerate进行多GPU训练(单机多卡)时,在保存模型结构的时候出现的问题
目录 问题描述问题分析问题解决 问题描述
我在保存模型结构的时候,先获取模型参数,然后再保存,代码如下: 图示代码是在训练主循环中的:
这种情况下会出现报错:
nboundLocalError: UnboundLocalErrorloc…
Pytorch多GPU并行训练: DistributedDataParallel
1 模型并行化训练
1.1 为什么要并行训练
在训练大型数据集或者很大的模型时一块GPU很难放下,例如最初的AlexNet就是在两块GPU上计算的。并行计算一般采取两个策略:一个是模型并行,一个是数据并行。左图中是将模型的不同部分放在不同GPU上进…
大模型并行训练指南:通俗理解Megatron-DeepSpeed之模型并行/数据并行
前言
本文可以看做是本文《千亿参数开源大模型 BLOOM 背后的技术,这是其英文原文》与相关论文的解读,但修正了部分细节错误,以及补充了大量的解释说明,使得其读起来一目了然、通俗易懂 第一部分 BLOOM与其背后的Megatron-DeepSpe…

Training - Kubeflow 的 PyTorchJob 配置 DDP 分布式训练 (ncclInternalError)
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://blog.csdn.net/caroline_wendy/article/details/137569332 Kubeflow 的 PyTorchJob 是 Kubernetes 自定义资源,用于在 Kubernetes 上运行 PyTorch 训练任务,是 K…
RetinaNet Examples:NVIDIA 一站式训练、推理及模型转换解决方案
retinanet-examples 是英伟达提供的目标检测工程范例,针对端到端 GPU 处理进行了优化:
使用基于 Python 多进程的 apex.parallel.DistributedDataParallel 加速分布式训练;apex.amp 优化混合精度训练;NVIDIA DALI 加速数据预处理…
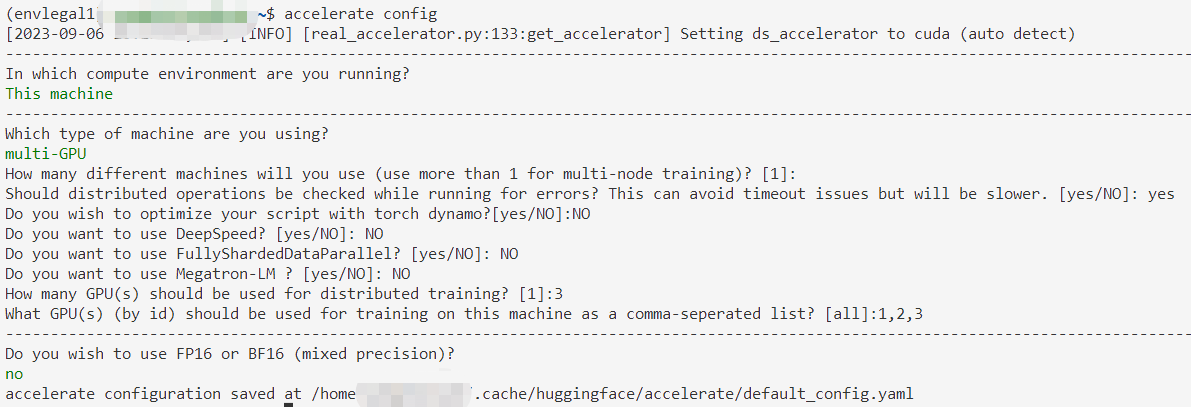
用huggingface.Accelerate进行分布式训练
诸神缄默不语-个人CSDN博文目录
本文属于huggingface.transformers全部文档学习笔记博文的一部分。 全文链接:huggingface transformers包 文档学习笔记(持续更新ing…)
本部分网址:https://huggingface.co/docs/transformers/m…
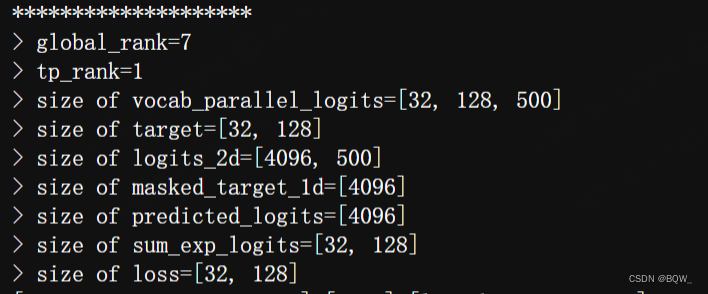
【Megatron-DeepSpeed】张量并行工具代码mpu详解(四):张量并行版Embedding层及交叉熵的实现及测试
相关博客 【Megatron-DeepSpeed】张量并行工具代码mpu详解(四):张量并行版Embedding层及交叉熵的实现及测试 【Megatron-DeepSpeed】张量并行工具代码mpu详解(三):张量并行层的实现及测试 【Megatron-DeepSpeed】张量并行工具代码mpu详解(一):…

PyTorch 1.8 发布,支持 AMD,优化大规模训练
内容导读 北京时间 3 月 4 日,PyTorch 官方博客发布 1.8 版本。据官方介绍,新版本主要包括编译器和分布式训练更新,同时新增了部分移动端教程。 本文首发自微信公众号:PyTorch 开发者社区
整体来看,本次版本更新涵盖 …